Microkernel
Summary
- Microkernel-based OS structure
- Potential for Performance Loss
- L3 Microkernel
- Reasons for Mach’s Expensive Border Crossing
- Thesis of L3 for OS Structuring
Microkernel-based OS structure
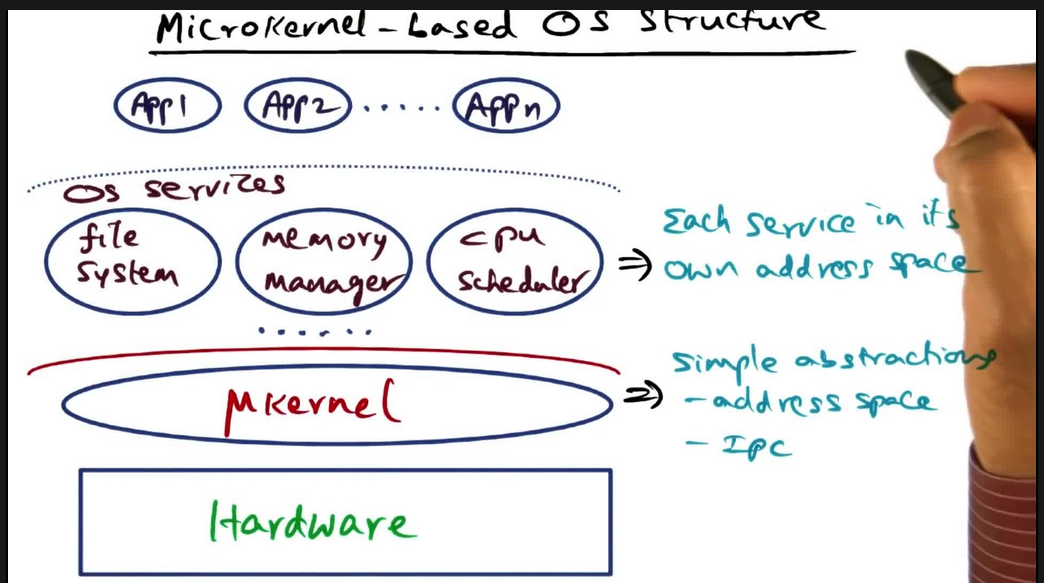
- Each OS Service in its own address space
- FS
- Memory Manager
- CPU Scheduler
- Simple abstractions below that in their own address space
- IPC
Potential for Performance Loss
- Border Crossings
- Implicit and Explicit
- Protected Procedure Calls (PPC)
- 100x normal procedure calls
- Services above microkernel talking to each other
- Minimally involves flushing TLB of processor
L3 Microkernel
Proof by construction to debunk myths about microkernel based os structure
Strkes Against Microkernel
- Kernel-User switches
- Border crossing cost
- Address space switches
- Basis for PPC for cross protection domain calls
- Thread switches and IPC
- Kernel mediation for PPC
- Memory Effects
- Loosing cache locality during thread switch / PPC / IPC
Debunking User Kernel Border Crossing Myth
- Empirical proof
- 123 processor cycles
Address Space Switches
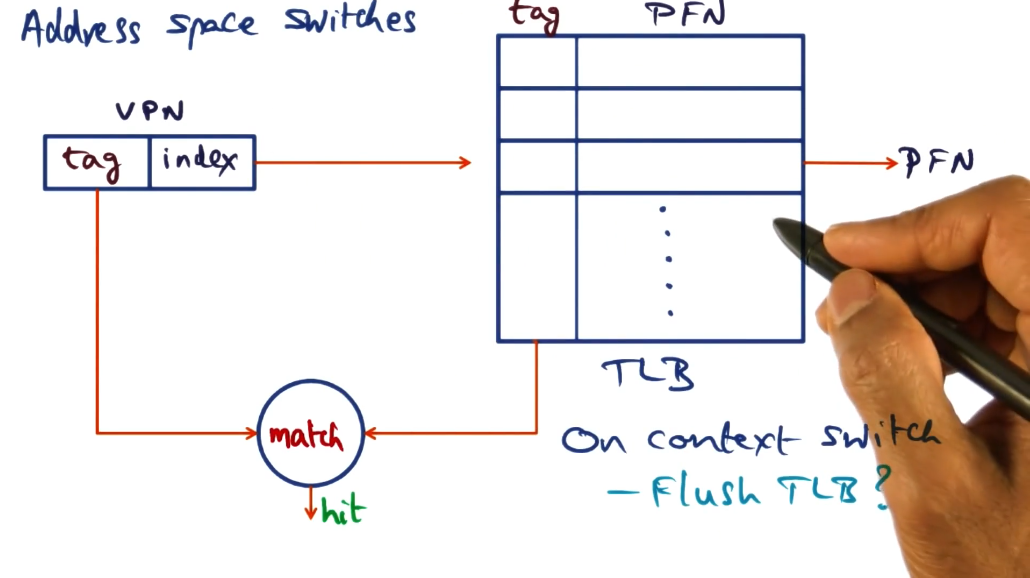
On context-switch, the different address space will change the mappings from virtual to physical addresses
Do we need to flush TLB?
- Depends on whether TLB has a way to flag is particular mappings belong to
specific process
- If we add ‘AddressSpaceTag’ to regular tag, it’s possible to not have to
flush TLB
- This may reduce total allocatable memory size per address space
- If we add ‘AddressSpaceTag’ to regular tag, it’s possible to not have to
flush TLB
Address Space Switches with Address Space Tagged TLB
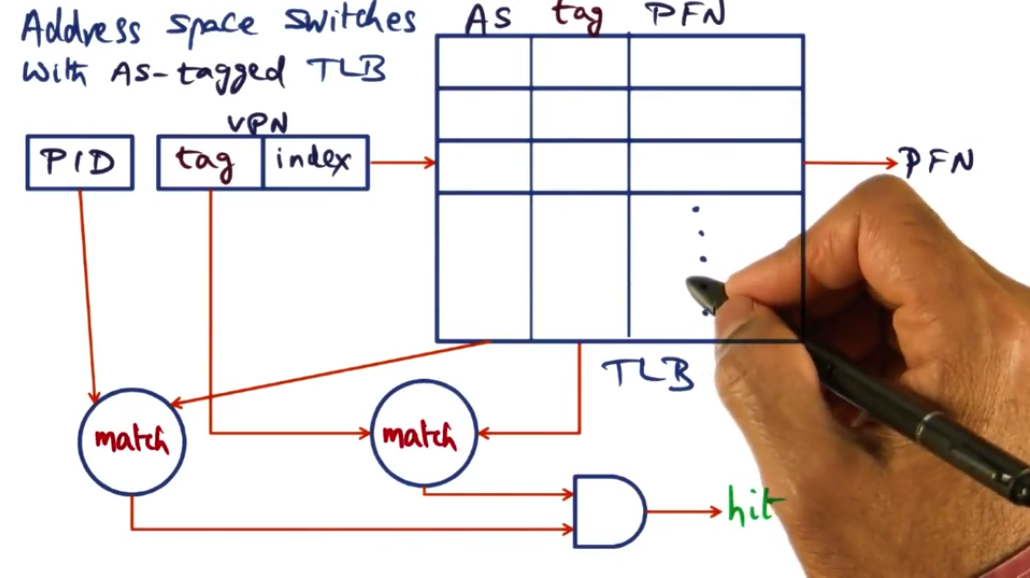
Liedtke’s Suggestions for Avoiding TLB Flush
Suggestions for Avoiding TLB Flush even if TLB is NOT AS-tagged
- Exploit architectural features
- Segment registers in x86/PowerPC
- Share hardware address space for protection domains
Large Protection Domains
Sometimes protection domains arge larger than hardware address space
- Have to do TLB flush on context switch
Implicit Costs >>> Explicit Costs
Upshot for Address Space Switching
- Small protection domains
- Can be made efficient by careful construction
- Large protection domains
- Switching cost not important
- cache effects and TLB effects dominate
This is how microkernel myth is debunked by construction
Thread Switches and IPC
- By construction shown to be competitive to SPIN and Exokernel
- Switch involves saving all volatile state of CPU
Memory Effects
small protection domains => warm caches
Reasons for Mach’s Expensive Border Crossing
- Focus on Portability
- code bloat => large memory footprint
- lesser locality => more cache misses
Thesis of L3 for OS Structuring
- Minimal abstraction in kernel
- Microkernel are processor-specific in implementation
- Non-portable
- Right set of abstractions and processor specific implementation
- efficient processor-independent abstractions at higher layers