Global Memory Systems
Summary
- Context for Global Memory System
- GSM Basics
- Behavior of Algorithm
- Geriatrics
- Implementation in Unix
- Data Structures
Context for Global Memory System
Memory Pressure:
- Different for each node
- How to use idle cluster mem
- remote memory access faster than disk
Memory Manager:
- Virtual Address to Physical Address or disk
Global Memory System:
- Virtual Address to Physical Address or disk or cluster memory
GSM Basics
Cache refers to physical memory (DRAM), not processor cache
Sense of Community to handle page faults at a node
Physical memory can be broken up into Local, Working memory or Global, Spare memory
Handling Page Faults Case 1
Common case:
- Page fault for X on node
- hit in global cache for some node Q
Adding X to local set, means we need to kick Y out of global section
Handling Page Faults Case 2
Common case with memory pressure at P
- Page fault for X on node P
- Swap LRU page Y for X
Handling Page Faults Case 3
Faulting Page on disk:
- Page fault for X on node P
- Page not in cluster
Send page being swapped out to node that has the globally oldest page
- Keep in mind that local copy could be dirty. If page is dirty it needs to be written to disk. If it’s clean, just drop it.
Handling Page Faults Case 3
Faulting page actively shared:
- Page fault for X on node P
- Page in some peer node Q’s local cache
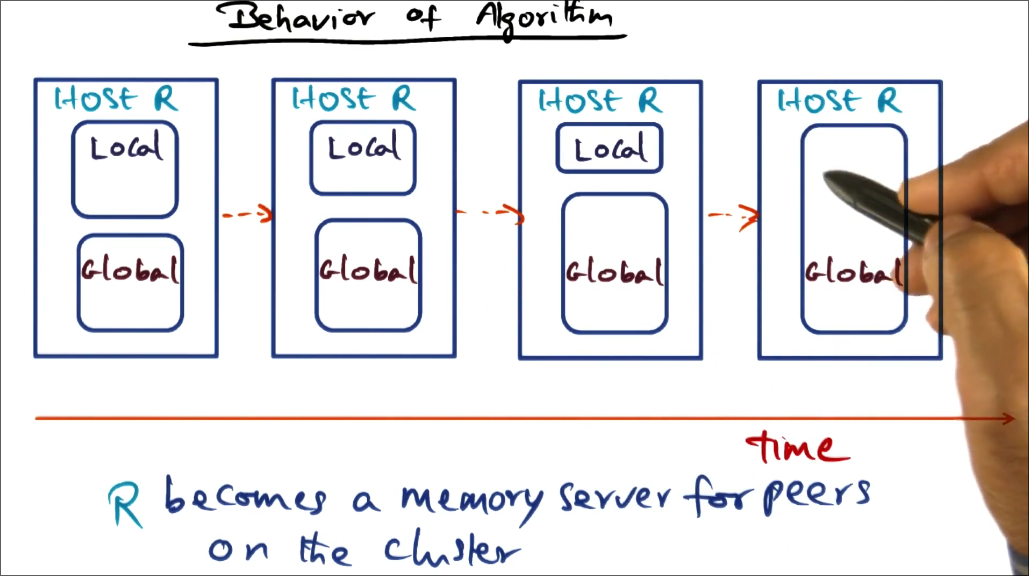
Behavior of Algorithm
overtime, idle nodes become memory servers
Geriatrics
Epoch parameters:
- T max duration
- M max replacements
Pick a manager per epoch
Each Epoch:
- Send age info to
Initiator - receive
- Min age of M oldest pages, and weight
Each node is given a weight for all the pages. The node with the highest weight has the highest number of pages that are going to be replaced. This means that node i relatively idle (from a memory perspective) and should be the next initiator.
Action at a node on page fault:
Think Globally, Act Locally
Implementation in Unix
GMS Integrated with DEC OSF/1
- Access to anonymous pages and FS mapped pages to go through GMS on reads
- Requires changes to VMM and UBC
- Writes remain unchanged
Maintaing age is tricky
- easier for UBC
- attach timestamp on fopen/fread calls
- intercepting explicit calls
- harder for VMM
- page faults are handled via hardware
- include daemon to dump info from TLB
Data Structures
Virtual Address -> UID (IP_Addr/disk_partition/i-node/offset)
- derived from VM + UBC
3 main data structures:
- PFD
- Page Frame Directory
- Like page table
- Converts UID to Page Frame Number
- has three states
- local private/shared
- global private
- on disk
- GCD
- Global Cache Directory
- Partitioned Hash Table
- Converts UID to node addr that has PFD
- POD
- Page Ownership Directory
- Replicated on all nodes
- Converts UID to GCD addr
Putting the Data Structures to Work
Common Case:
- page not shared
- GCD is on same node as POD
What about misses?
- Only happens when POD is changing
- Uncommon
- Simply re-run loop
Page Eviction
Paging Daemon:
- Freelist below threshold
- put page oldest pages
- update GCD, PFD for the UIDs