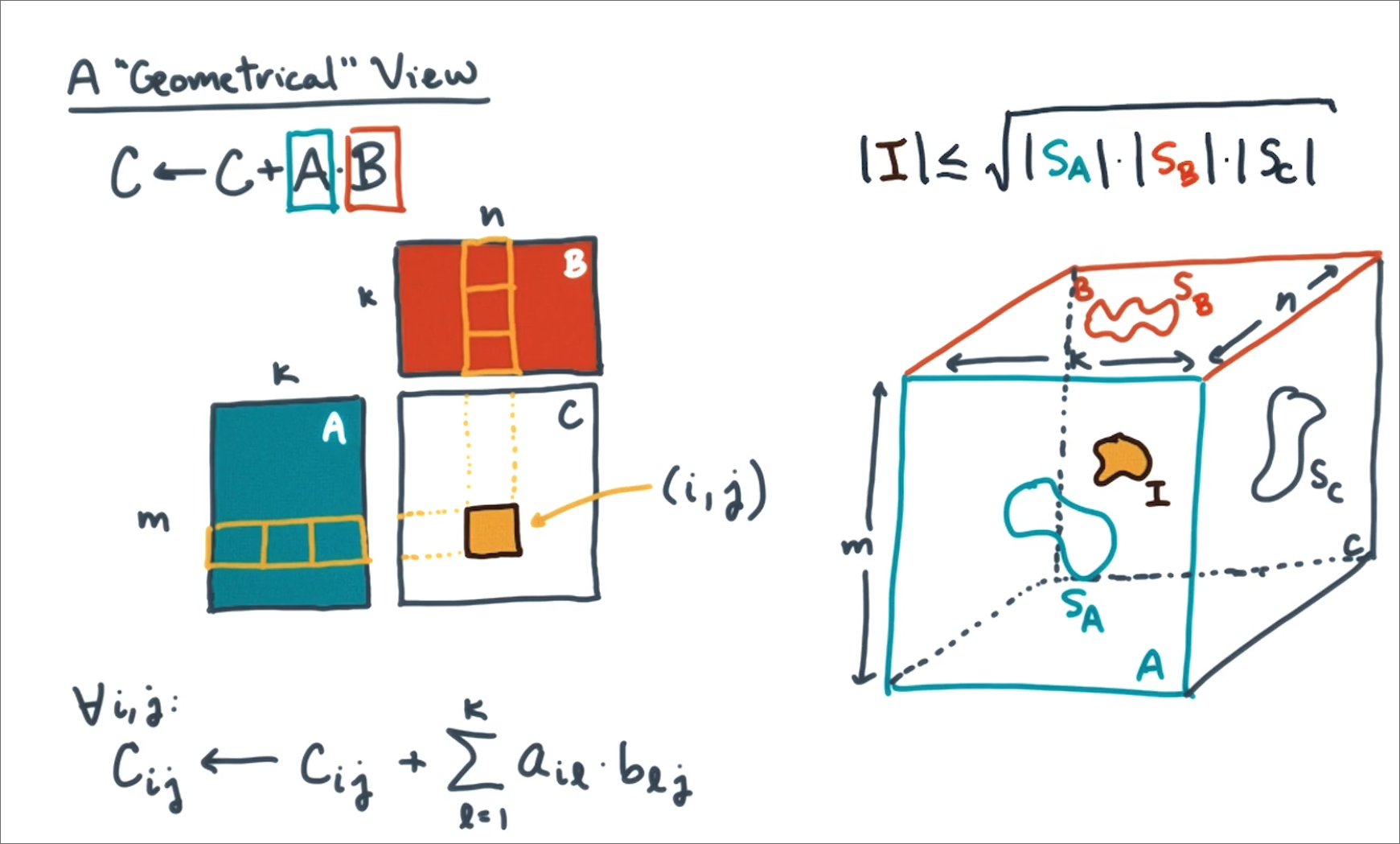
Given an m by k matrix A, k by n matrix B, and an m by n matrix C, compute a
dot product for each row of A and each column of B and append to C
C <- C + AB
1 . .
2 . .
5 . .
3 4 -2 6
. . .
. . .
for i <- 1 to m do
for j <- 1 to n do
for l <- 1 to k do
C[i,j] <- C[i,j] + A[i, l] * B[l, j]
Top two loops can be parfors, and innermost loop can be a reduction
parfor i <- 1 to m do
parfor j <- 1 to n do
let T[1:k] = temp_array
parfor l <- 1 to k do
T[l] <- A[i, l] * B[l, j]
C[i,j] <- C[i,j] + reduce(T[:])
Algorithms
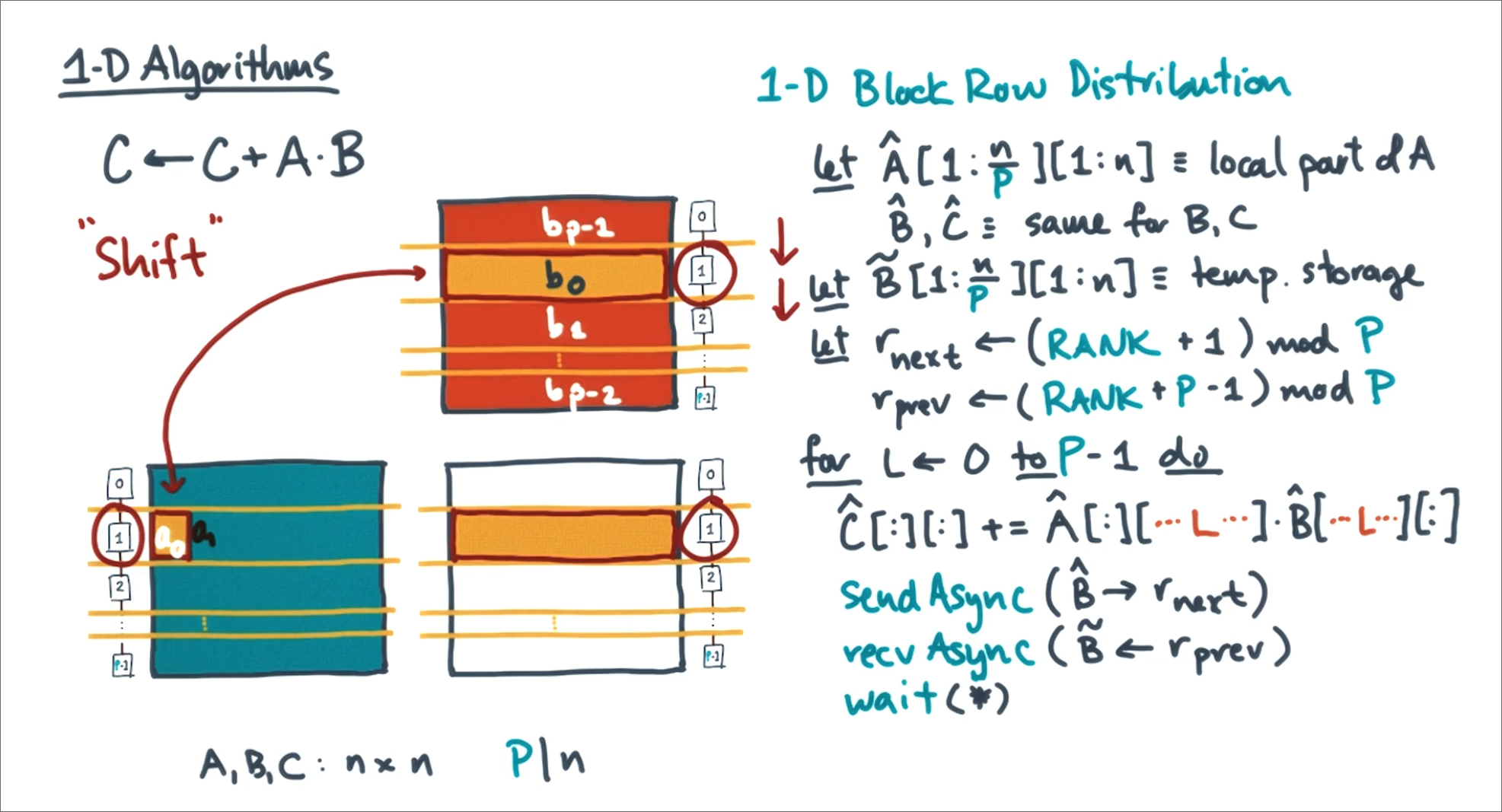
1D Algorithms
Start by distributing work across rows to P-1 processors. Each processor gets
n/P consecutive rows of each matrix operand.
The most work any one processor is to update an entire row of C, using an
entire row of B, and one subblock of A. Then we can shift the row of b we are
looking at to use another subblock of A.
Swap Bs after Wait
Parallel Efficiency speedup / P A parallel system is efficient if parallel speedup is a constant. Higher constants are better.
Isoefficiency function The function of P that n has to satisfy in order to have constant parallel efficiency.
2D Algorithms
SUMMA
Assume a 2d mesh mesh network, Operands are distributed as normal, and each
node is responsible for updating a part of the C matrix that it owns.
for (l = 0; l < N/s; l += s) do
broadcast(A[rank][l:l+s], owner)
broadcast(B[rank][l:l+s], owner)
localUpdate(...)
2D algorithm is asymptotically better than 1D, Tree is slightly better than bucket
Memory for 1D algo:
Memory for 2D algo:
Lower bound on Communication
Imagine a machine with P nodes, connected by some topology, where each node has
M words of main memory, during the entire distributed matrix multiply, any node
does W muliplications.
How many words MUST this node send or receive?
Imagine a timeline where a nodes actions alternate between computation and
communication. That timeline can be broken up into L phases where the node
sends/recvs exactly M words (except the last phase which might only have < M)
What is the largest number of multiplies that each phase can possibly do?
By Looms-Whitney:
It’s possible that A already has M words in its memory, does some computations,
evicts M words, then recv’s M more words and does more computations.
How many phases are there?
If matrices are of size m,n,k, respectively, at least one node has to do
multiplications, so there is some
node where
If M is distributed evenly across all nodes (and assuming ):
Total time for communication
Since the largest message a node can send is of size M,
Beating Lower Bound
Increasing memory from
allows you to use a 3D algorithm that broadcasts volumes of computations,
rather than surfaces.